环境要求
- Solr7.3
- IKAnalyzer(ik原作者的项目2012年就已经停止更新,推荐使用 ik-analyzer-solr7)
前提
一个已经搭建好的Solr服务器,可参考:Solr(一)基于tomcat的solr环境搭建 适配Solr7.3的中文分词器,这里推荐 github 的 magese/ik-analyzer-solr7,直接把项目下载下来解压即可。
认识schema
在Solr中配置分词器需要在schema配置文件中进行配置,在低版本的solr中schema是schema.xml,而solr7.3中则是名为 managed-schema 不带后缀的文件,schema.xml和managed-schema的配置其实大同小异,下面就以schema.xml为例讲解一下其中的各个配置的作用。(来源Solr索引库l配置文件schema.xm要点翻译)
schema.xml是Solr一个配置文件,它包含了你的文档所有的字段,以及当文档被加入索引或查询字段时,这些字段是如何被处理的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
<?xml version="1.0" encoding="UTF-8" ?>
略...
<!--
这是Solr的schema文件,应该命名为schema.xml,并且在solr home的conf目录下
(如,默认在./solr/conf/schema.xml).
有关如何根据需要定制化该文件,请参照:
http://wiki.apache.org/solr/SchemaXml 性能须知: 这里包含了很多实际应用不需要的可选项。 为改善性能,你可以:
- 尽量将所有仅用于搜索,而不用于实际返回的字段设置stored="false";
- 尽量将所有仅用于返回,而不用于搜索的字段设置indexed="false";
- 去掉所有不需要的copyField 语句;
- 为了达到最佳的索引大小和搜索性能,对所有的文本字段设置indexed="false",
使用copyField将他们拷贝到“整合字段”name="text"的字段中,使用整合字段进行搜索;
- 使用server模式来运行JVM,同时将log级别调高, 避免输出所有请求的日志。
-->
<schema name="example" version="1.5">
略...
<fields>
<!-- fields各个属性说明:
name: 必须属性 - 字段名
type: 必须属性 - <types>中定义的字段类型
indexed: 如果字段需要被索引(用于搜索或排序),属性值设置为true
stored: 如果字段内容需要被返回,值设置为true
docValues: 如果这个字段应该有文档值(doc values),设置为true。文档值在门
面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致生成
索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。
然而也有一些使用限制:目前仅支持StrField, UUIDField和所有 Trie*Fields,
并且依赖字段类型, 可能要求字段为单值(single-valued)的,必须的或者有默认值。
multiValued: 如果这个字段在每个文档中可能包含多个值,设置为true(像ID这种不重复的字段就需要定义为false)
termVectors: [false] 设置为true后,会保存所给字段的相关向量(vector)
当使用MoreLikeThis时, 用于相似度判断的字段需要设置为stored来达到最佳性能.
termPositions: 保存和向量相关的位置信息,会增加存储开销
termOffsets: 保存 offset 和向量相关的信息,会增加存储开销
required: 字段必须有值,否则会抛异常
default: 在增加文档时,可以根据需要为字段设置一个默认值,防止为空
-->
<!-- 字段名由字母数字下划线组成,且不能以数字开头。两端为下划线的字段为保留字段,
如(_version_)。
-->
<field name="id" type="string" indexed="true" stored="true"
required="true" multiValued="false" />
<field name="title" type="text_general" indexed="true"
stored="true" multiValued="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="author" type="text_general" indexed="true" stored="true"/>
<field name="keywords" type="text_general" indexed="true" stored="true"/>
<field name="category" type="text_general" indexed="true" stored="true"/>
<field name="url" type="text_general" indexed="true" stored="true"/>
<field name="last_modified" type="date" indexed="true" stored="true"/>
<!-- 注意: 为了节省空间,这个字段默认不被索引, 因使用copyField被拷贝到了名为text的字段中
。用于内容返回和高亮。搜索时使用text字段
-->
<field name="content" type="text_general" indexed="false"
stored="true" multiValued="true"/>
<!-- 整合字段(catchall field), 包含其他可搜索的字段 (通过copyField实现) -->
<field name="text" type="text_general" indexed="true"
stored="false" multiValued="true"/>
<!-- 保留字段,不能删除,否则报错 -->
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<!-- 文档的唯一标识,可理解为主键,除非标识为required="false", 否则值不能为空-->
<uniqueKey>id</uniqueKey>
<!-- 拷贝需要索引的字段到整合字段中 -->
<copyField source="title" dest="text"/>
<copyField source="author" dest="text"/>
<copyField source="description" dest="text"/>
<copyField source="keywords" dest="text"/>
<copyField source="content" dest="text"/>
<copyField source="url" dest="text"/>
<!-- 动态字段允许solr检索那些没有明确定义的字段。动态字段就像一个常规的字段,
除了它有一个带有通配符的名字。在作为索引文档时,与任何明确定义的字段都不匹配的字段可以与动态字段匹配。
例如,假设您的模式中包含一个具有 *_i 名称的动态字段。如果您尝试使用 cost_i 字段对文档进行索引,
但架构中没有定义明确的 cost_i 字段,则该 cost_i 字段将具有*_i 定义的字段类型和分析,
也就是后缀是_i的字段会匹配到名称为*_i的动态字段定义的字段类型。-->
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pint" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_s_ns" type="string" indexed="true" stored="false" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<types>
<!-- 字段类型定义 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0"
positionIncrementGap="0"/>
略...
<!-- Thai,泰语类型字段 -->
<fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ThaiWordFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="lang/stopwords_th.txt" />
</analyzer>
</fieldType>
<!-- Turkish,土耳其语类型字段 -->
<fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false"
words="lang/stopwords_tr.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
</analyzer>
</fieldType>
<!-- Chinese,需要我们自己配置,整合mmseg4j就配置在这里 -->
</types>
<!-- 文档相似度判断依赖于文档相似度得分。 一个自定义的 Similarity 或 SimilarityFactory
可以在这里指定, 但是默认的设置已经适合大多数应用。可以参考:
http://wiki.apache.org/solr/SchemaXml#Similarity
-->
<!--
<similarity class="com.example.solr.CustomSimilarityFactory">
<str name="paramkey">param value</str>
</similarity>
-->
</schema>
总结起来就几个要点
1
2
3
4
5
6
7
8
9
<uniqueKey>id</uniqueKey>:指定某个字段是唯一的字段 。
<fieldType ></fieldType>:定义字段类型。
<field name=" " type=" "/>:定义字段。
<dynamicField name=" " type=" " indexed="true" stored="true"/>:定义动态字段。
<copyField source=" " dest=" " />:复制字段。
构建中文分词器
理解schema的配置后就开始构建自己的分词器吧
步骤
一、下载并解压IKAnalyzer
使用上面的下载地址下载IK,并解压,将IK目录下src/main/resources中的5个文件拷贝到Solr的WEB-INF/classes/目录下
1
2
3
4
5
① IKAnalyzer.cfg.xml
② ext.dic
③ stopword.dic
④ ik.conf
⑤ dynamicdic.txt
下载IK jar包,将jar拷贝到Solr的WEB-INF/lib目录下
二、配置IK中文分词器
schema中加入IK分词器配置
1
2
3
4
5
6
7
8
9
10
11
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
启动、测试
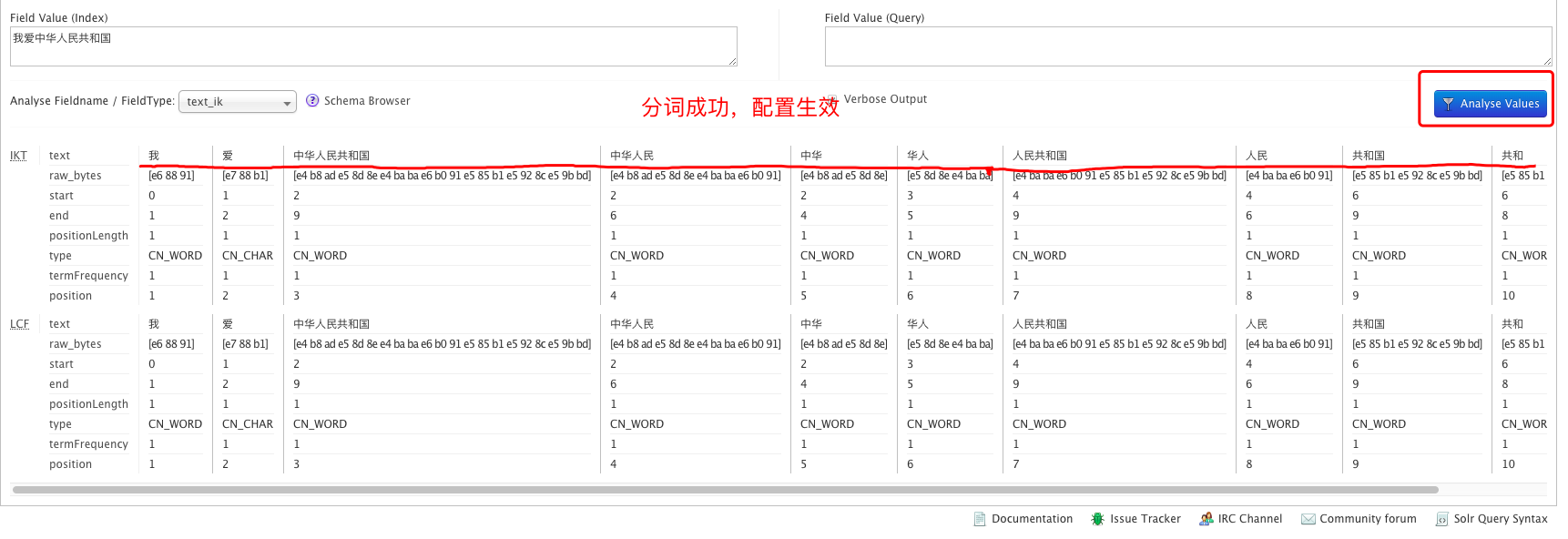
启动Solr访问页面,选择用我们自己配置的text_ik分词器:

输入文本进行测试