环境要求
- Hadoop2.6
- centos7
前提
准备好三台centos系统,配置如下
| 主机名 | centos1 | centos2 | centos3 |
|---|---|---|---|
| ip | centos1的ip | centos2的ip | centos3的ip |
centos7修改主机名命令:
hostnamectl set-hostname xxx
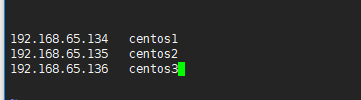
配置三个centos的ip映射,修改/etc/hosts,加入如下配置:
1
2
3
centos1的ip centos1
centos2的ip centos2
centos3的ip centos3
分别配置好三个centos的jdk环境、hadoop环境(参考Hadoop环境搭建),过程略(使用命令scp操作很简单),配置服务器免密登录(参考Linux免密码操作)
步骤
三台服务器任务分配: centos1|centos2|centos3 —|—|— 部署一个NameNode、一个DataNode|部署一台DataNode | 部署一台DataNode
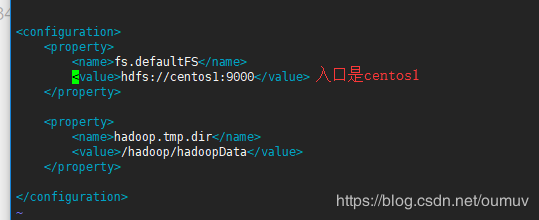
一、修改三台centos的etc/hadoop/core-site.xml
因为NameNode在centos1中,所以入口统一是在centos1:
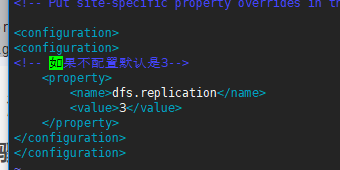
二、修改三台centos的etc/hadoop/hdfs-site.xml
三、编辑三台centos的etc/hadoop/slaves
在里面加入三台centos的主机名或ip地址(DataNode所在的服务器):
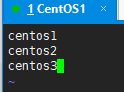
启动、测试
启动前先在centos1(NameNode)中执行初始化:
hadoop namenode -format
在centos1中执行命令启动hdfs
start-dfs.sh
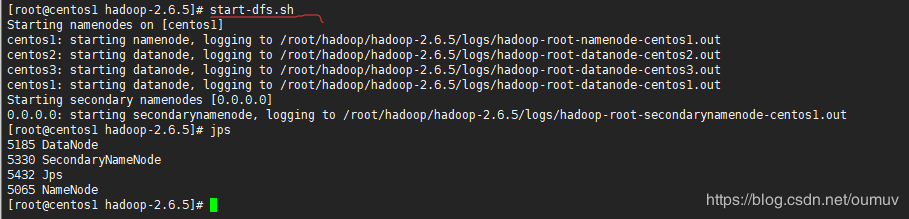
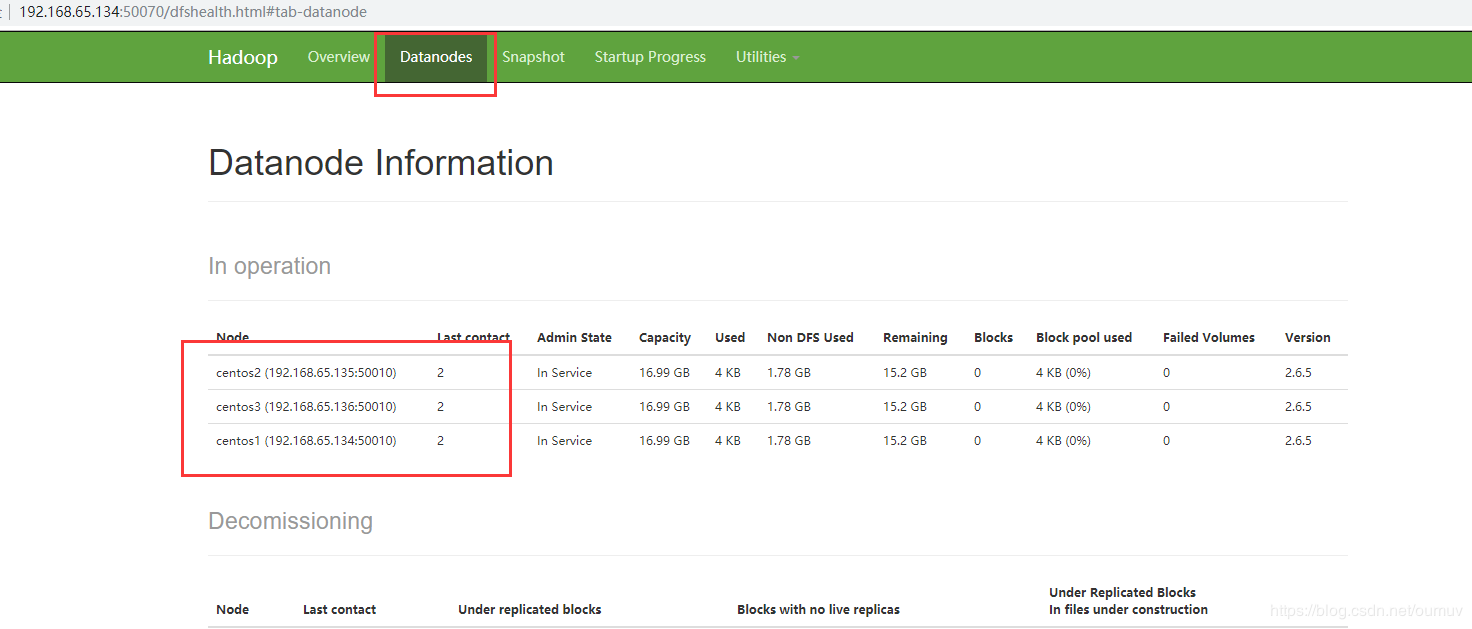
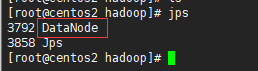
去centos2和centos3执行查看发现都有一个DataNode节点
访问web界面: